
Accord Inter Annotateur ou comment contrôler la fiabilité des données évaluées pour l'IA ?

Qu'est-ce que l’Accord Inter Annotateur (ou IAA pour "Inter Annotator Agreement") et pourquoi est-il important ?
Un Accord Inter Annotateur (IAA) est une mesure de la concordance ou de la cohérence entre chaque annotation produite par différents annotateurs travaillant sur la même tâche ou le même ensemble de données, dans le cadre de la préparation d'un jeu de données d'entraînement pour l'IA. L'Accord Inter Annotateur évalue dans quelle mesure les annotateurs sont d'accord sur les annotations attribuées à un ensemble de données (ou 🔗 dataset) spécifique.
L'importance de l'Accord Inter Annotateur réside dans sa capacité à donner une indication scientifique et précise des évaluations. Dans les domaines précédemment mentionnés, notamment le développement de produits IA s'appuyant sur des données volumineuses, les décisions et les conclusions reposent souvent sur chaque annotation fournie par des 🔗 annotateurs humains. Sans un moyen de mesurer et de garantir la cohérence de ces annotations, les résultats obtenus peuvent être biaisés ou peu fiables !
L'IAA permet de quantifier et de contrôler la cohérence de chaque annotation. Cela contribue à améliorer la qualité des données annotées et la robustesse des analyses qui en découlent, et bien sûr des résultats produits par vos modèles IA. En identifiant les divergences entre les annotateurs, l'Accord Inter Annotateur permet également de cibler les points de désaccord et de clarifier les critères d'annotation. Cela peut améliorer la cohérence de toute annotation produite par la suite, au cours du cycle de préparation des données pour l'IA.
Comment l'Inter Annotator Agreement contribue-t-il à assurer la fiabilité des annotations en IA ?
L'Accord Inter Annotateur est une métrique qui contribue à la fiabilité des évaluations de plusieurs façons :
Mesure de la cohérence des annotations
L'IAA fournit une mesure quantitative de la concordance entre chaque annotation attribuée par différents annotateurs. En évaluant cette concordance, on peut déterminer la fiabilité des évaluations et identifier les domaines où il y a des divergences entre les annotateurs.
Identification des erreurs et des ambiguïtés
En comparant chaque annotation, c'est-à-dire les métadonnées produites par des annotateurs différents sur un ensemble de données spécifique, l'Accord Inter Annotateur permet d'identifier les erreurs potentielles. Et par la même occasion, les ambiguïtés dans les consignes d'annotation (ou manuels d'annotation) ainsi que les lacunes dans la formation des annotateurs. En corrigeant ces erreurs, on améliore la qualité des métadonnées, des datasets produits, et in fine de l'IA !
Clarification des critères d'annotation
L'Accord Inter Annotateur peut aider à clarifier les critères d'annotation en identifiant les points de désaccord entre les annotateurs. En examinant ces points de désaccord, il est possible de clarifier les consignes d'annotation puis de fournir une formation supplémentaire aux annotateurs. C’est une bonne pratique pour améliorer la cohérence des évaluations !
Optimisation du processus d'annotation
En contrôlant régulièrement l'Accord Inter Annotateur, il est possible d'identifier les tendances et les problèmes récurrents dans les évaluations, dans les ensembles de données en cours de construction. Cela permet d'optimiser le processus d'annotation, qu'il s'agisse d'images ou de 🔗 vidéos notamment, en mettant en œuvre au fil de l'eau des mesures correctives pour améliorer la fiabilité des évaluations des jeux de données sur le long terme.
-hand-innv.png)
Quelles sont les méthodes courantes utilisées pour évaluer la fiabilité d'une annotation ?
Plusieurs méthodes sont couramment utilisées pour évaluer la fiabilité de chaque annotation. Voici quelques-unes des méthodes les plus répandues :
Coefficient de Cohen's Kappa
Le coefficient de Cohen's Kappa est une mesure statistique qui évalue l'accord entre deux annotateurs corrigé par la possibilité d'accord aléatoire. Il est calculé en comparant la fréquence observée d'accord entre les annotateurs à la fréquence attendue d'accord par hasard. Ce coefficient varie de -1 à 1, où 1 indique un accord parfait, 0 indique un accord équivalent à celui obtenu par hasard, et -1 indique un désaccord parfait. Cette mesure est largement utilisée pour évaluer la fiabilité d'annotations binaires ou catégorielles, telles qu'une annotation de présence ou d'absence, ou encore une annotation de classification dans des catégories prédéfinies (par exemple : chien, chat, tortue, etc.).
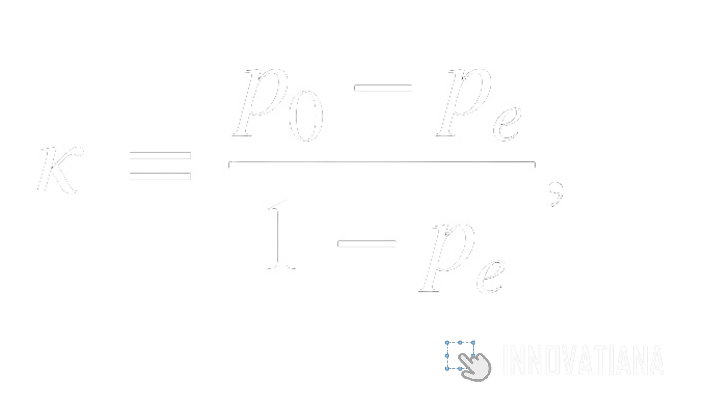
Coefficient alpha de Krippendorff
Le coefficient alpha de Krippendorff est une mesure de fiabilité inter annotateur qui évalue l'accord entre plusieurs annotateurs pour des données catégorielles, ordinales ou nominales. Contrairement au coefficient de Cohen's Kappa, il peut être appliqué à des ensembles de données comportant plus de deux annotateurs. Le coefficient alpha de Krippendorff tient compte de la taille de l'échantillon, de la diversité des catégories et de la possibilité d'accord par hasard. Il varie de 0 à 1, où 1 indique un accord parfait et 0 indique un désaccord complet. Cette mesure est particulièrement utile pour évaluer la fiabilité des annotations dans des situations où plusieurs annotateurs sont impliqués, comme dans les études inter annotateurs.
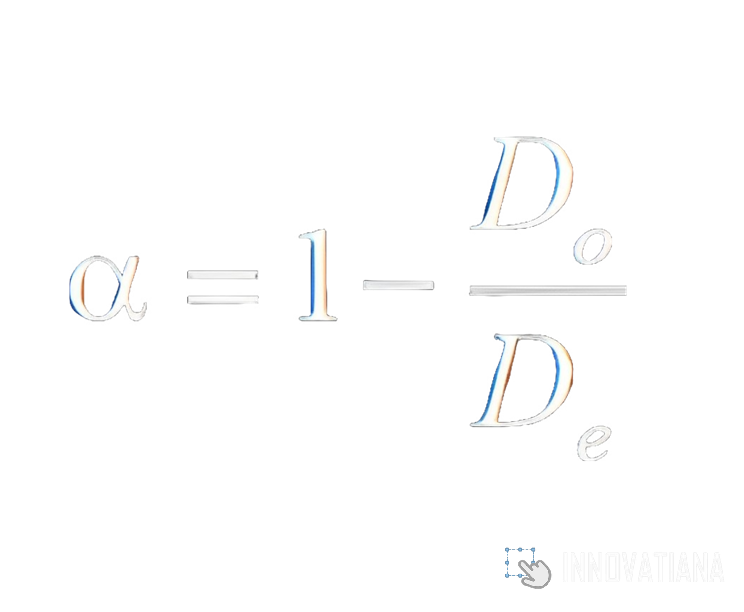
Coefficient de corrélation intra-classe (CCI)
Le coefficient de corrélation intra-classe est une mesure de fiabilité utilisée pour évaluer la concordance entre les annotations continues ou ordinales de plusieurs annotateurs. Il est calculé en comparant la variance entre les annotations des annotateurs à la variance totale. Cela donne une estimation de la proportion de variance attribuable à l'accord entre les annotateurs. Le CCI varie de 0 à 1, où 1 indique un accord parfait et 0 indique un désaccord complet. Cette mesure est particulièrement utile pour évaluer la fiabilité des mesures quantitatives ou ordinales, telles que les évaluations de performances ou les évaluations de qualité.
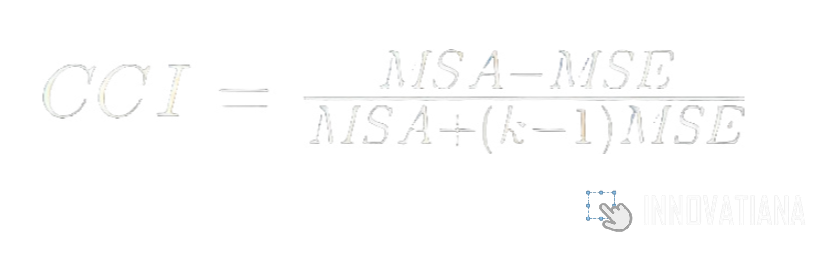
Analyse des discordances
L'analyse des discordances consiste à examiner les cas où les annotateurs diffèrent dans leurs annotations, pour identifier les sources potentielles de désaccord. Cela peut inclure l'examen des cas où les annotateurs ont interprété les consignes différemment, les cas où les consignes étaient ambiguës ou les cas où les annotateurs manquaient de formation sur la tâche d'annotation. Cette analyse permet de comprendre les raisons des divergences entre les annotateurs et d'identifier des moyens d'améliorer la cohérence des annotations à l'avenir.
Analyse de la fiabilité interne
L'analyse de la fiabilité interne évalue la cohérence interne des annotations en examinant la concordance entre différentes annotations d'un même annotateur. Cela peut inclure des mesures telles que la cohérence intra-annotateur,qui évalue la stabilité des annotations d'un annotateur sur plusieurs évaluations de la même tâche. Cette analyse permet de déterminer si les annotations d'un annotateur sont cohérentes et fiables dans le temps.
Analyse des marges d'erreur
L'analyse des marges d'erreur évalue la variabilité des annotations en examinant les écarts entre les annotations d'un même annotateur sur des éléments similaires. Cela peut inclure l'examen des cas où un annotateur a attribué des annotations différentes à des éléments qui devraient être similaires selon les consignes d'annotation. Cette analyse permet de quantifier la précision des annotations et d'identifier les éléments les plus sujets à l'erreur. Cela peut donner des indications préciseuses pour l'amélioration des instructions d'annotation ou la formation des annotateurs.
Comment utiliser l'Accord Inter Annotateur de façon efficace dans les processus d'annotation pour l'IA ?
Pour mettre en place un processus efficace d'annotation d'IA, l'Accord Inter Annotateur peut être utilisé comme une métrique de contrôle qualité. Pour mettre en place cette métrique, il faut suivre plusieurs étapes clés. Tout d'abord, il est important de définir clairement les consignes d'annotation en spécifiant les critères à suivre pour annoter les données. Ces consignes doivent être précises, complètes et faciles à comprendre pour les annotateurs (ou Data Labelers). Pour une meilleure efficacité, il est préférable de fournir à ces derniers une formation approfondie sur l'annotation et sur la tâche à effectuer. Il est primordial que les Data Labelers comprennent parfaitement les consignes et qu'ils soient capables de les appliquer de manière cohérente !
Avant de lancer le processus d'annotation à grande échelle, il est recommandé d'effectuer un pilote, c'est-à-dire un test avec un petit ensemble de données et plusieurs annotateurs. Cela permet d'identifier et de corriger les éventuels problèmes dans les consignes d'annotation ou dans la compréhension des annotateurs. Une surveillance continue du processus d'annotation est également nécessaire pour détecter les éventuels problèmes ou incohérences. Cela peut être réalisé en examinant périodiquement un échantillon aléatoire des annotations produites par les annotateurs.
Si des problèmes ou des incohérences sont identifiés, il faut réviser et clarifier les consignes d'annotation en fonction des retours des annotateurs. L'utilisation d'outils d'annotation appropriés peut également faciliter le processus et garantir la cohérence des annotations. Ces outils peuvent inclure des plates-formes en ligne spécialisées dans l'annotation de données ou des logiciels personnalisés développés en interne.
Une fois que les annotations sont complètes, il est nécessaire d'évaluer la fiabilité interannotateur en utilisant des méthodes telles que le coefficient de Cohen's Kappa ou le coefficient alpha de Krippendorff. Cela permettra de quantifier l'accord entre les annotateurs et d'identifier les éventuelles sources de désaccord. Enfin, il convient d'analyser les résultats de l'évaluation de la fiabilité inter annotateur pour identifier les erreurs et les incohérences potentielles dans les annotations. Il faut par la suite les corriger en révisant les annotations concernées et en clarifiant les consignes d'annotation si nécessaire.
💡 Vous souhaitez en savoir plus et apprendre à construire des datasets de qualité ? 🔗 Découvrez notre article !
Comment l'Accord Inter Annotateur est-il utilisé dans le domaine de l'Intelligence Artificielle ?
Dans le domaine de l'Intelligence Artificielle (IA), l'Accord Inter Annotateur joue un rôle de premier plan pour garantir la qualité et la fiabilité des ensembles de données annotés, utilisés pour entraîner et évaluer les modèles d'IA.
Entraînement des modèles d'IA
Les modèles d'IA nécessitent des ensembles de données annotés pour être entraînés et pour un apprentissage automatique efficace. C’est le cas pour les réseaux de neurones profonds, les algorithmes d'apprentissage automatique et les systèmes de traitement du langage naturel. L'Accord Inter Annotateur est utilisé pour garantir la fiabilité et la qualité des annotations dans ces ensembles de données. Cela permet d'obtenir des modèles plus précis et fiables.
Évaluation des performances des modèles
Une fois les modèles d'IA entraînés, ils doivent être évalués sur des ensembles de données de test pour mesurer leurs performances. L'Accord Inter Annotateur est également utilisé dans ce contexte pour garantir que les annotations dans les ensembles de test sont fiables et cohérentes. C’est la garantie d’une évaluation précise des performances des modèles.
Correction des erreurs de modélisation
Lors de l'analyse des résultats des modèles d'IA, il est souvent nécessaire d'identifier et de corriger les erreurs de modélisation. L'Accord Inter Annotateur peut être utilisé pour évaluer la qualité des annotations dans les ensembles de données annotés et identifier les domaines où les modèles produisent des résultats incorrects. Cela permet de comprendre les lacunes des modèles et d'améliorer leur précision.
Développement d'un jeu de données spécifiques
Dans certains cas, il est nécessaire de créer un jeu de données spécifiques pour des tâches d'IA particulières. L'Accord Inter Annotateur est alors utilisé pour garantir la qualité et la cohérence des annotations dans ce jeu de données. Cela permet de développer des modèles d'IA adaptés à des domaines ou des applications spécifiques.
Ces métriques permettent de mesurer la précision et la fiabilité des annotations en tenant compte des accords partiels et des données incomplètes, ce qui est particulièrement utile pour des tâches complexes de labellisation des données. Par exemple, dans les études de référence pour des applications comme la détection d'objets dans les images annotées par des annotateurs professionnels ou crowdsourcés, l'IAA aide à évaluer la précision relative de chaque annotateur, révélant ainsi des classes d'objets plus difficiles à annoter et influençant directement la performance des modèles de Computer Vision entraînés à partir de ces données.
Cela montre à quel point cet indicateur est fondamental non seulement pour garantir la cohérence des annotations, mais aussi pour améliorer la qualité globale des données et des modèles d'apprentissage automatique qui en dépendent. L'IAA est LA métrique à utiliser pour la plupart de vos cycles de préparation et de révision des données pour l'IA !
Quels sont les avantages et les inconvénients de l'utilisation de l'IAA ?
L'utilisation de l'Accord Inter Annotateur présente à la fois des avantages et des inconvénients dans différents domaines.
Avantages
En utilisant l'Accord Inter Annotateur de manière proactive, les spécialistes de l'IA ou Data Scientists peuvent garantir la qualité et la cohérence des évaluations dans divers domaines, ce qui renforce la validité des analyses et, potentiellement, la performance des modèles. Voici quelques avantages :
1. Fiabilité des évaluations
L'Accord Inter Annotateur permet la mesure de la concordance entre les annotations de différents annotateurs, ce qui renforce la confiance dans les évaluations réalisées. Par exemple, dans le domaine de la recherche académique, où des études reposent souvent sur l'analyse d'annotations manuelles, l'IAA garantit que les résultats sont basés sur des données fiables et cohérentes. De même, dans le développement de systèmes d'IA, des ensembles de données annotés de manière fiable sont essentiels pour l'entraînement de modèles précis.
2. Identification des erreurs
En comparant les annotations de plusieurs annotateurs, l'Accord Inter Annotateur permet de repérer les incohérences et les erreurs dans les données annotées. Par exemple, dans le domaine de l'analyse de données, il peut révéler des divergences dans l'interprétation des informations. Cela permet d'identifier les erreurs et de les corriger. Par la même occasion, cela permet d’améliorer la qualité des données et d’éviter les biais potentiels dans les analyses ultérieures.
3. Clarification des consignes d'annotation
Lorsque des annotateurs produisent des annotations divergentes, cela peut signaler des ambiguïtés dans les consignes d'annotation. En identifiant les points de désaccord, l'IAA aide à clarifier et à préciser les consignes, ce qui améliore la cohérence des annotations à l'avenir. Par exemple,dans le domaine de la 🔗 classification d'images, des divergences dans l'attribution de certaines classes peuvent indiquer un besoin de réviser les directives pour une meilleure interprétation.
4. Optimisation du processus d'annotation
En surveillant régulièrement l'IAA, il est possible d'identifier les tendances et les problèmes récurrents dans les évaluations de données de tous types. Cela permet d'apporter des améliorations continues au processus d'annotation, en mettant en place des mesures correctives pour améliorer la qualité des évaluations à long terme. Par exemple, si l'IAA révèle une baisse soudaine de la concordance entre les annotateurs, cela peut indiquer un besoin de révision des consignes ou de formation supplémentaire des annotateurs.
Inconvénients
Bien que l'IAA offre de nombreux avantages pour garantir la qualité et la fiabilité des évaluations dans différents domaines, cette métrique présente également des inconvénients.
Coût en temps et en ressources
La mise en place d'un processus de labellisation et des métriques associées telles que l'IAA peut demander beaucoup de temps et de ressources. Il faut recruter et former des annotateurs qualifiés, superviser le processus d'annotation, collecter et traiter les données annotées,et analyser les métriques de façon régulière pour optimiser la production des données et métadonnées. Ce processus peut être chronophage et nécessiter un investissement financier important, surtout dans des domaines où les données sont nombreuses ou complexes.
Complexité des analyses
L'analyse de métriques comme l'IAA peut se révéler complexe, ,notamment lorsque plusieurs annotateurs sont impliqués ou lorsque les données annotées sont difficiles à interpréter. Il faut souvent utiliser des méthodes statistiques avancées pour évaluer la concordance entre les annotations et interpréter les résultats de manière appropriée. Cela peut nécessiter des compétences spécialisées en statistiques ou en analyse de données, ce qui peut être un défi pour certaines équipes de Data Labeling.
Sensibilité aux biais humains
Les processus de labellisation de données peuvent être influencés par les biais individuels des annotateurs, tels que les préférences personnelles, les interprétations subjectives des consignes d'annotation ou les erreurs humaines. Par exemple, un annotateur peut être plus enclin à attribuer une certaine annotation en raison de ses propres opinions ou expériences, ce qui peut biaiser les modèles d'IA. Il est important de prendre des mesures pour minimiser ces biais, comme la formation des annotateurs et la clarification des consignes d'annotation.
Limitations dans certains contextes
Dans certains domaines ou pour certaines tâches, l'utilisation d'une métrique come l'IAA peut être limitée en raison de la nature des données annotées. Par exemple, dans des domaines où les données sont rares ou difficiles à obtenir, il peut être difficile de constituer un ensemble de données annotées de manière fiable. De même, dans des domaines où les tâches d'annotation sont complexes ou subjectives, il peut être difficile de recruter des annotateurs expérimentés capables de produire des annotations de haute qualité.
Possibilité de désaccords persistants
Malgré les efforts pour clarifier les consignes d'annotation et harmoniser les pratiques, il peut arriver que les annotateurs continuent à avoir des opinions divergentes sur certaines annotations. Cela peut entraîner des désaccords persistants entre les annotateurs et rendre difficile la résolution des divergences. Dans certains cas, cela peut compromettre la qualité globale des évaluations et donc des datasets !
En tenant compte de ces inconvénients, il est important de mettre en place des mesures pour atténuer leurs effets et maximiser les avantages de l'utilisation d'un indicateur comme l'IAA dans différentes applications. Cela peut inclure une formation approfondie des annotateurs, une clarification régulière des consignes d'annotation, une surveillance étroite du processus d'annotation, et surtout une analyse minutieuse des résultats de l'IA pour identifier et corriger les problèmes potentiels.
En conclusion
En conclusion, l'Accord Inter Annotateur (IAA) est un outil essentiel pour garantir la qualité et la fiabilité des données annotées utilisées dans le domaine de l'intelligence artificielle. C'est une métrique qui tend à s'imposer au sein des équipes de Data Labeling les plus matures.
En mesurant la cohérence entre les annotateurs, l'IAA permet de s'assurer que les ensembles de données sont fiables et exemptes de biais, contribuant ainsi à l'efficacité des modèles d'IA développés. Malgré des défis, notamment en termes de coût et de complexité, l'importance de l'IAA réside dans son utilité en tant que métrique permettant d'améliorer continuellement le processus d'annotation.
En utilisant l'IAA à bon escient, les équipes de Data Scientists et spécialistes IA peuvent optimiser les processus d'annotation, renforçant ainsi la qualité des datasets produits. Le rôle de l'IAA dans le développement de données d'entraînement et l'évaluation de modèles d'IA est donc indéniable, faisant de cet indicateur un véritable pilier dans la préparation de données de haute qualité pour les technologies futures.


