

En transformant des éléments visuels en données textuelles, l'OCR ouvre de nouvelles perspectives dans le domaine de l'analyse de données visuelles et des tâches d'annotation de données.
Qu'est-ce que l'OCR ?
La Reconnaissance Optique de Caractères (OCR) est une technologie permettant la conversion des documents physiques contenant du texte en fichiers électroniques modifiables. On commence par numériser un document à l'aide d'un scanner ou d'un appareil photo. Ensuite, les algorithmes intégrés analysent l'image pour reconnaître les caractères imprimés.
Une fois les caractères identifiés, l'OCR les convertit en texte éditable, généralement dans un format de fichier tel que Word ou PDF. Cette technologie est largement utilisée pour la conversion de documents papier en fichiers électroniques. L’objectif est de faciliter leur stockage en les intégrant dans une base de données, afin de permettre de réaliser des recherches ou des éditions.
Qu’est-ce qui fait l’importance de l’OCR ?
L’OCR prend toute son importance dans ses diverses utilisations, entre autres :
Numérisation et conservation des documents
Comme susmentionné, l'OCR permet de convertir des documents papier en formats électroniques, facilitant ainsi leur stockage et leur conservation à long terme. Cela aide à préserver des documents importants et historiques qui pourraient autrement se détériorer avec le temps.
Accessibilité
L'OCR rend le contenu des documents imprimés accessible aux personnes malvoyantes ou aveugles. Elle permet notamment la conversion du texte en formats lisibles par des logiciels de synthèse vocale ou des afficheurs braille.
Recherche et analyse de contenu
Une fois que le texte est converti en format électronique, il devient plus facile de le rechercher, de le trier et de l'analyser. Cela facilite la recherche d'informations spécifiques dans de vastes ensembles de documents. Ce qui peut être grandement utile dans des domaines tels que la recherche académique, juridique, médicale ou commerciale.
-hand-innv.png)
Qu'est-ce qui rend l'OCR si important (bien que parfois sous-estimé) dans l'ère de l'IA ?
Dans l'ère de l'IA, l'OCR devient encore plus important en raison des avancées technologiques qui l'accompagnent, notamment :
Intégration dans les workflows automatisés
L'intégration de l' OCR dans les systèmes alimentés par l'IA permet d'automatiser des tâches comme classifier de documents, extraire du texte ou autres informations et effectuer un traitement de données. Cela peut accélérer les processus métier, réduire les erreurs humaines et libérer du temps pour des tâches plus stratégiques.
Entraînement de modèles d'IA
Analyse de données non structurées
De nombreuses informations précieuses se trouvent dans des documents non structurés tels que des rapports, des contrats, des formulaires, … L' OCR permet de rendre ces données accessibles à l'analyse par des algorithmes d'IA. Cela ouvre de nouvelles possibilités pour la prise de décision basée sur les données et l'innovation.
Comment l'OCR façonne-t-il les tâches d'annotation de données ?
Pour de nombreux cas d'usage, l'OCR (Reconnaissance Optique de Caractères) participe activement à la manière dont les tâches d'annotation de données sont façonnées. Quelques illustrations ci-après :
Prétraitement des données
Augmentation des données
L'OCR peut être utilisé pour 🔗 augmenter les ensembles de données en convertissant des documents non textuels en texte extrait. Cela permet d'augmenter la variété et la quantité des données disponibles pour l'entraînement des modèles d'IA. Cela peut, par la même occasion, améliorer les performances de ces modèles.
Validation et correction des annotations
Lorsque des annotateurs humains travaillent sur des tâches d'annotation, l' OCR peut être utilisé pour valider ou corriger les annotations produites. Par exemple, si un annotateur a mal annoté une partie du texte dans une image, l' OCR peut être utilisé pour vérifier si le texte extrait correspond à l'annotation. Cela peut aider à garantir la qualité des données annotées.
Amélioration de l'efficacité
En utilisant l'OCR pour extraire du texte à partir d'images, les tâches d'annotation peuvent être rendues plus efficaces. Plutôt que de demander aux annotateurs de saisir manuellement le texte à annoter, ils peuvent se concentrer sur la tâche spécifique d'annotation. C’est une excellente façon d’accélérer le processus global de traitement des données.
Adaptation aux besoins spécifiques
L'OCR peut être adapté pour répondre aux besoins spécifiques des tâches d'annotation. Par exemple, dans le cas de documents contenant des langues ou des polices de caractères particulières, des modèles d' OCR personnalisés peuvent être développés pour améliorer la précision de l'extraction de texte. Cela est particulièrement important dans les projets d'annotation de données sensibles à la qualité des données (c'est-à-dire, la très grande majorité des projets !).
Comment les premiers systèmes OCR ont-ils ouvert la voie à la technologie actuelle ?
Les premiers systèmes OCR ont posé les bases pour le développement de la technologie actuelle. Ils ont surmonté de nombreux défis techniques et ont introduit des concepts fondamentaux qui continuent d'être utilisés aujourd'hui.
Reconnaissance de caractères basée sur des règles
Les premiers systèmes OCR utilisaient souvent des approches basées sur des règles pour reconnaître les caractères. Ces approches comprenaient la définition de règles spécifiques pour reconnaître des formes de caractères basées sur des caractéristiques telles que la taille, la forme et la disposition des traits.
Bien que ces méthodes étaient limitées en termes de précision et de capacité à traiter des polices de caractères variées, elles ont posé les bases pour les développements ultérieurs dans le domaine.
Modèles statistiques
Plus tard, les systèmes OCR ont commencé à utiliser des modèles statistiques pour améliorer la précision de la reconnaissance des caractères. Ces modèles ont été entraînés sur de grandes quantités de données pour apprendre les caractéristiques des caractères et des mots dans différents contextes.
Cette approche a permis d'améliorer considérablement la précision de la reconnaissance optique des caractères, en particulier dans des environnements où les polices de caractères et les styles d'écriture peuvent varier.
Utilisation de réseaux neuronaux
Les progrès récents dans le domaine de l'apprentissage profond ont conduit à l'adoption de réseaux neuronaux pour la reconnaissance de caractères. Ces réseaux neuronaux ont démontré des performances remarquables dans la reconnaissance de texte. C’est en particulier le cas des réseaux de neurones convolutifs (CNN) et des réseaux de neurones récurrents (RNN).
Ces modèles ont considérablement amélioré la précision de l' OCR et ont permis de traiter une grande variété de polices de caractères et de styles d'écriture. Cela, en utilisant des architectures profondes et des techniques d'entraînement avancées sur de grandes quantités de données.
Adaptation aux données spécifiques
Les systèmes OCR modernes intègrent souvent des mécanismes d'adaptation aux données spécifiques pour améliorer la précision de la reconnaissance. Cela peut inclure l'entraînement de modèles OCR sur des données spécifiques à un domaine ou à une langue particulière. Cela inclut également l'utilisation de techniques d'adaptation continue pour ajuster les modèles en fonction des nouvelles données observées dans des scénarios en production.
L'OCR : au-delà de la numérisation des documents, quelles autres applications révolutionne-t-il ?
Au-delà de la simple numérisation des documents, l' OCR apporte des innovations significatives à de nombreuses autres applications.
Traduction automatique
L'OCR est souvent utilisé en combinaison avec des systèmes de traduction automatique pour traduire des documents imprimés dans différentes langues. En convertissant d'abord le texte en format électronique à l'aide de l' OCR, les systèmes de traduction automatique peuvent ensuite traduire le texte dans la langue désirée.
Extraction d'informations
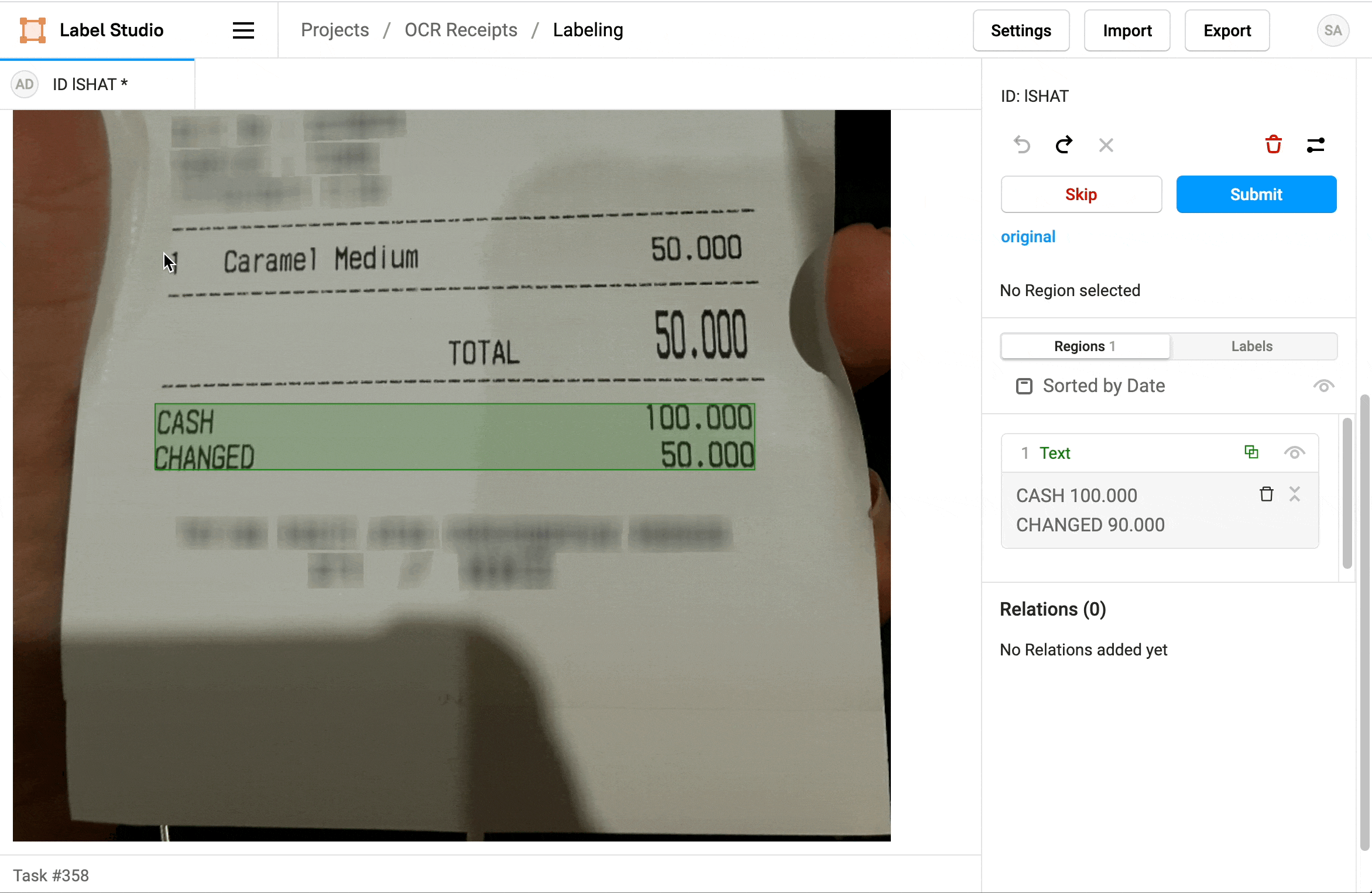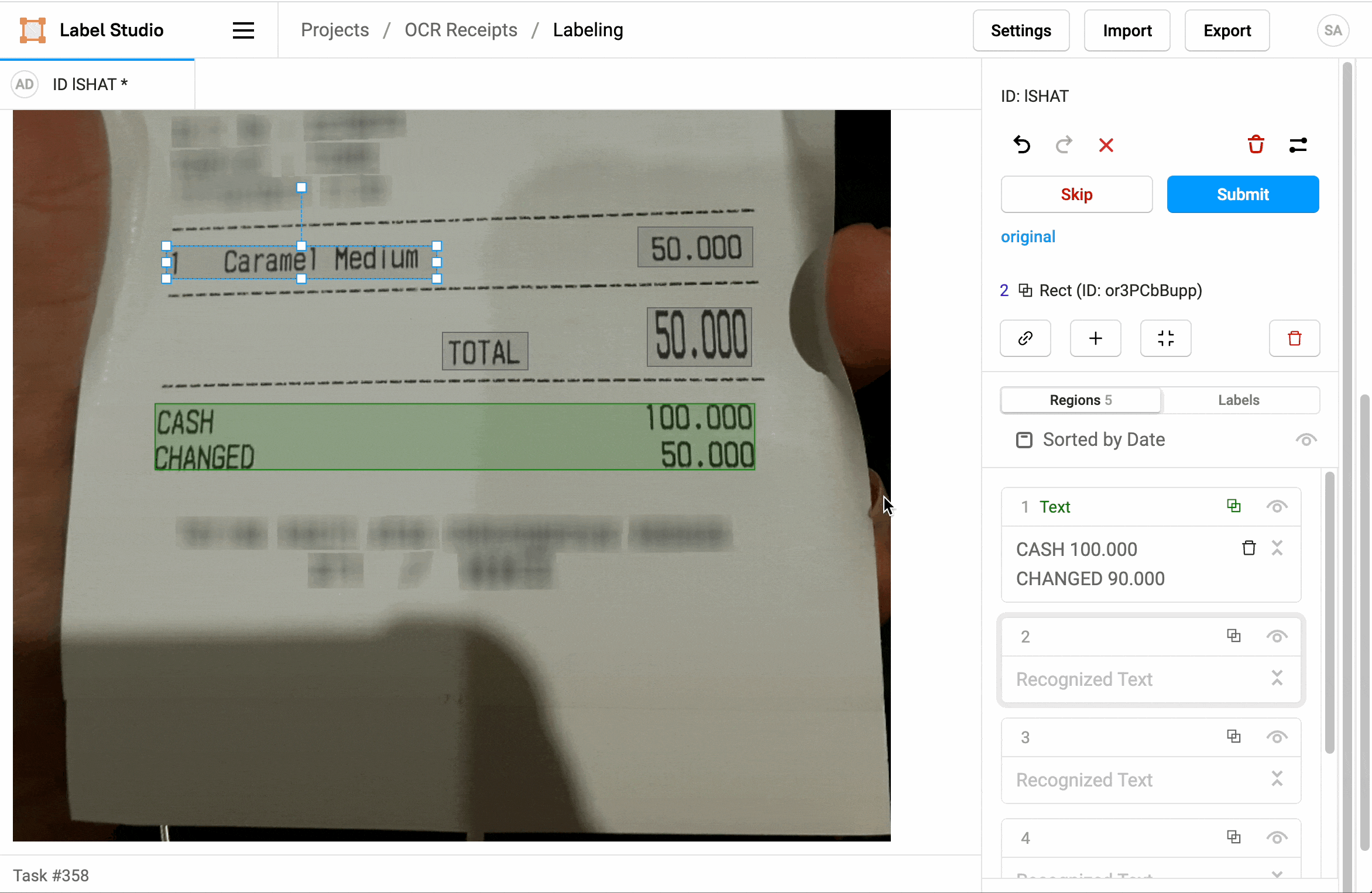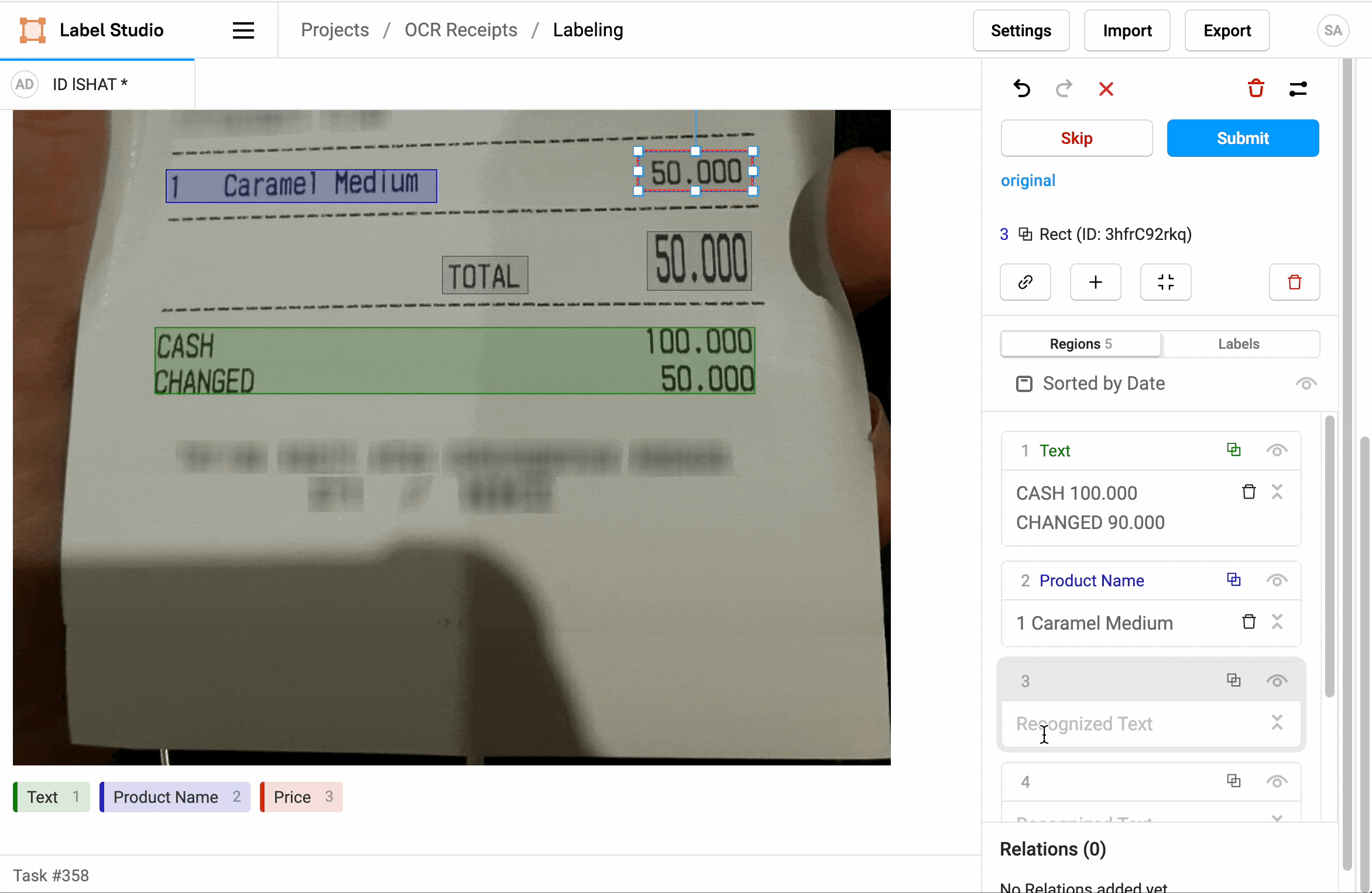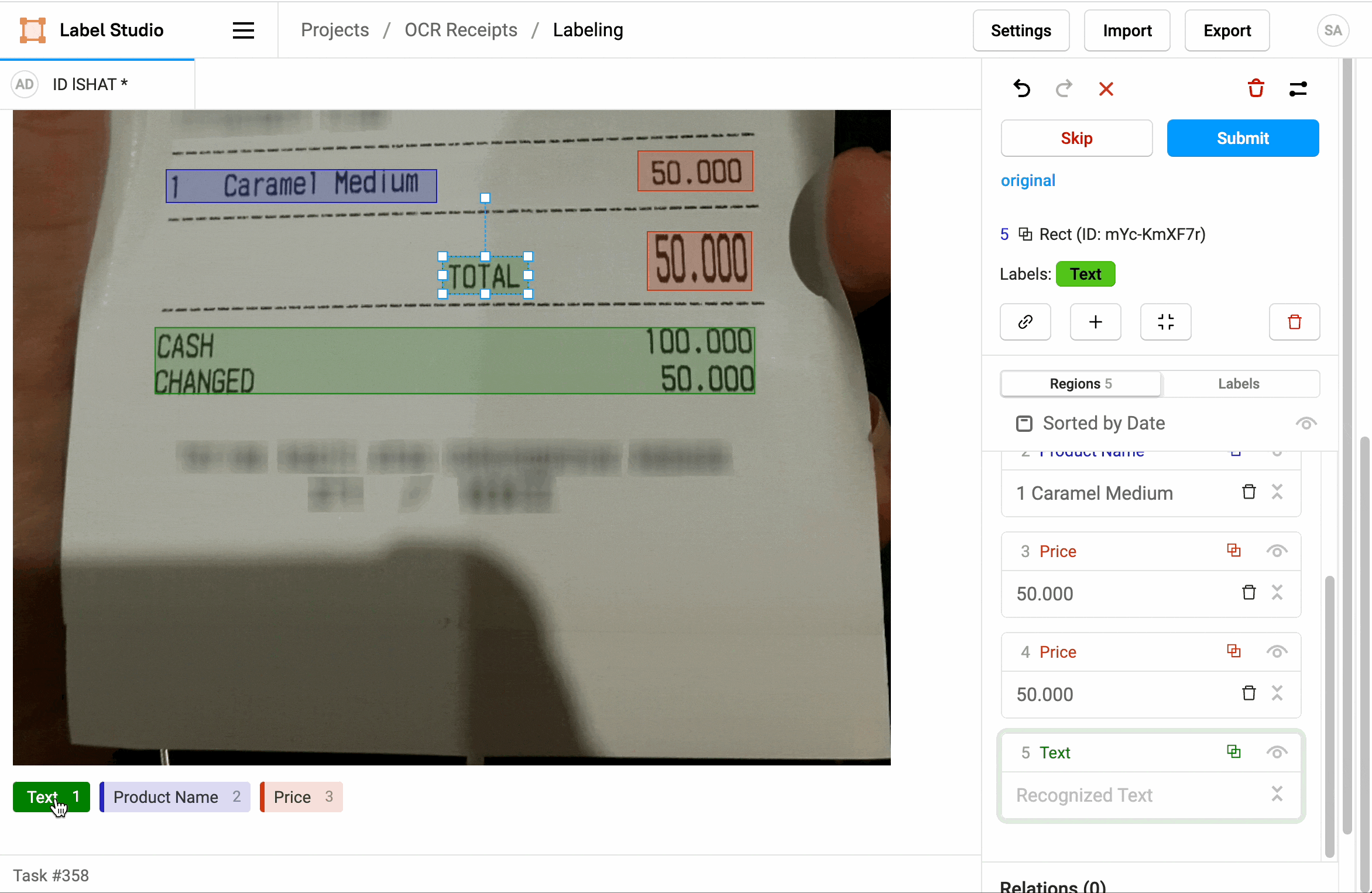
L' OCR peut être utilisé pour extraire des informations spécifiques à partir de documents, tels que des factures, des formulaires ou des reçus ou ticket de caisse. Par exemple, dans le domaine de la comptabilité, l' OCR peut être utilisé pour extraire automatiquement les montants, les dates et d'autres informations pertinentes à partir de factures numérisées. Cela peut considérablement accélérer les processus de traitement des données.
Reconnaissance de texte dans les images et les vidéos
L' OCR peut également être utilisé pour extraire du texte à partir d'images ou de 🔗 vidéos. Cela est utile dans des cas où il peut être nécessaire de rechercher du texte spécifique dans les enregistrements vidéo. Ou encore, dans la reconnaissance automatique de plaques d'immatriculation à partir d'images de caméras de surveillance.
Quelles nouvelles frontières l'OCR pourrait-il franchir dans les années à venir ?
Dans les années à venir, l' OCR pourrait franchir de nouvelles frontières grâce à l'évolution rapide de la technologie, et en particulier de l'intelligence artificielle. A l'heure où nous écrivons ces lignes, les techniques de développement d'IA sont renouvelées toutes les 2 semaines, ou presque ! L'intégration avec d'autres domaines de l'intelligence artificielle et de l'informatique pourront également avoir leur rôle à jouer.
Reconnaissance avancée des documents manuscrits
Les progrès dans les techniques de traitement d'image et d'apprentissage automatique pourraient permettre une reconnaissance plus précise des documents manuscrits. Cela, même dans des conditions difficiles telles que des styles d'écriture variés, des documents endommagés ou encore des langues avec des caractères complexes.
Reconnaissance multimodale
L'intégration de l' OCR avec d'autres modalités sensorielles pourrait permettre une reconnaissance multimodale plus robuste et contextuellement plus riche. Il pourrait s’agir de la reconnaissance d'objets dans les images, la reconnaissance vocale et la compréhension du langage naturel. Cela ouvrirait de nouvelles possibilités dans des domaines tels que la réalité augmentée, la voiture autonome et les interfaces utilisateur intelligentes.
OCR basé sur le Deep Learning
L'utilisation d'architectures de réseaux neuronaux profonds et de techniques d'apprentissage profond pourrait améliorer considérablement la précision de l' OCR. En particulier dans des scénarios difficiles tels que la reconnaissance de documents avec des polices de caractères variées, des langues non latines et des scripts complexes.
OCR en temps réel
Les progrès dans les technologies de traitement d'image et les architectures matérielles pourraient permettre le déploiement d' OCR en temps réel sur des dispositifs mobiles et des systèmes embarqués. Cela ouvrirait de nouvelles possibilités dans des applications telles que la réalité augmentée (VR), la traduction en temps réel et l'assistance visuelle pour les personnes malvoyantes ou aveugles.
OCR adaptatif et auto-apprenant
L'OCR pourrait devenir plus adaptatif et auto-apprenant. Et ce, en utilisant des techniques d'apprentissage continu pour s'adapter automatiquement à de nouveaux types de documents, de langues et de styles d'écriture. Cela pourrait permettre une meilleure généralisation et une plus grande robustesse de l' OCR dans des environnements variés.
Protection de la vie privée et de la sécurité des données
Avec l'augmentation de l'utilisation de l' OCR pour traiter des documents sensibles, il y aura probablement un accent croissant sur le développement de techniques de protection de la vie privée et de la sécurité des données. Cela a pour but de garantir que les informations confidentielles comme des informations médicales, financières ou juridiques, ne sont pas compromises lors du processus de reconnaissance.
Conclusion
L'OCR (Optical Character Recognition), ou Reconnaissance Optique de Caractères, est une technologie qui transforme les documents imprimés en texte éditable. Elle ouvre la voie à de nombreuses applications pratiques. En analysant les images des documents, l' OCR identifie et convertit les caractères en texte numérique, facilitant la recherche, la traduction et l'automatisation des processus.
Bien qu'elle puisse faire face à divers défis techniques, tels que la précision de la reconnaissance et la variabilité des langues, l' OCR continue d'évoluer grâce aux avancées de l'intelligence artificielle et du traitement d'image. Ainsi, l'OCR promet de rendre l'information imprimée plus accessible, manipulable et exploitable que jamais.


